
Resumen ejecutivo
Pídeles a cuatro modelos de IA distintos que recomienden software de CRM en Estados Unidos y en Alemania. Los productos que mencionan pueden ser similares, pero los sitios web que citan para respaldar esas recomendaciones son casi por completo diferentes. Algo se pierde entre los mercados, y no es necesariamente el producto. Incluso en el software inherentemente global, entre el 81 % y el 93 % de los dominios de origen son exclusivos de un único país.
Lo comprobamos en varias categorías de software global (como CRM, ciberseguridad, automatización de marketing, análisis de datos, herramientas de colaboración) en 12 países, 7 idiomas y 4 grandes modelos de IA. Analizamos más de 1 millón de fuentes en esta industria para llegar a las conclusiones de este informe.
Para las empresas de SaaS, los proveedores de tecnología y cualquiera que gestione la visibilidad de marca en IA entre mercados, la implicación es clara. Una presencia sólida de fuentes en un país no se traslada a otro, ni siquiera para una categoría de producto que es fundamentalmente la misma en todas partes. Las estrategias de contenido localizado no son opcionales. Son la única forma de aparecer en las respuestas de IA mercado por mercado.
La autoridad de tu marca no tiene pasaporte.
Puntos destacados
- En promedio, menos de 1 de cada 10 dominios de origen se comparten entre dos países cualesquiera: incluso para productos como Salesforce y HubSpot, la gran mayoría de los sitios web citados por la IA nunca aparecen en los resultados de otro país.
- 23,9 % es la mayor coincidencia de fuentes entre cualquier par de países (Canadá–EE. UU.): el par más similar del conjunto de datos sigue difiriendo en 3 de cada 4 dominios citados.
- Brecha de 2,8x entre los modelos más y menos localizados: Copilot comparte el 6,7 % de las fuentes de software entre fronteras; Grok comparte el 18,8 %. Los mismos prompts, los mismos países, estrategias de fuentes radicalmente distintas.
- 3,6 % es la menor coincidencia de fuentes entre cualquier par de países (Francia–Suecia): dos países europeos, ambos preguntando por el mismo software global, comparten menos de 1 de cada 25 dominios citados.
- El 79,5 % de las citas de software de EE. UU. provienen de dominios .com: pero incluso en Francia y los Países Bajos, donde .com es más bajo, sigue representando entre el 44 % y el 46 % de todas las fuentes de software.
La mayoría de las fuentes de IA del SaaS son exclusivas de un único país
La conclusión central: cuando los modelos de IA citan fuentes para productos de software global, la gran mayoría de esas fuentes no aparecen en los resultados de ningún otro país. En promedio, en todos los pares de países, cada modelo comparte entre el 6,7 % y el 18,8 % de sus dominios citados entre fronteras, lo que significa que el par típico de países discrepa en más de 4 de cada 5 fuentes.
| Modelo | Coincidencia media de fuentes |
|---|---|
| Microsoft Copilot | 6,7 % |
| Google AI Overviews | 7,9 % |
| ChatGPT | 9,5 % |
| Grok (xAI) | 18,8 % |
No se trata de temas de nicho ni culturalmente específicos. Software de CRM, plataformas de ciberseguridad, herramientas de colaboración; los productos en sí son globales. Salesforce no se convierte en un producto distinto cuando cruzas una frontera. Pero el contenido web del que los modelos de IA se nutren para hablar de estos productos es casi totalmente diferente de un país a otro.
Incluso Grok, el modelo más global, comparte menos de 1 de cada 5 dominios de origen entre fronteras. En el caso de Copilot, es menos de 1 de cada 14.
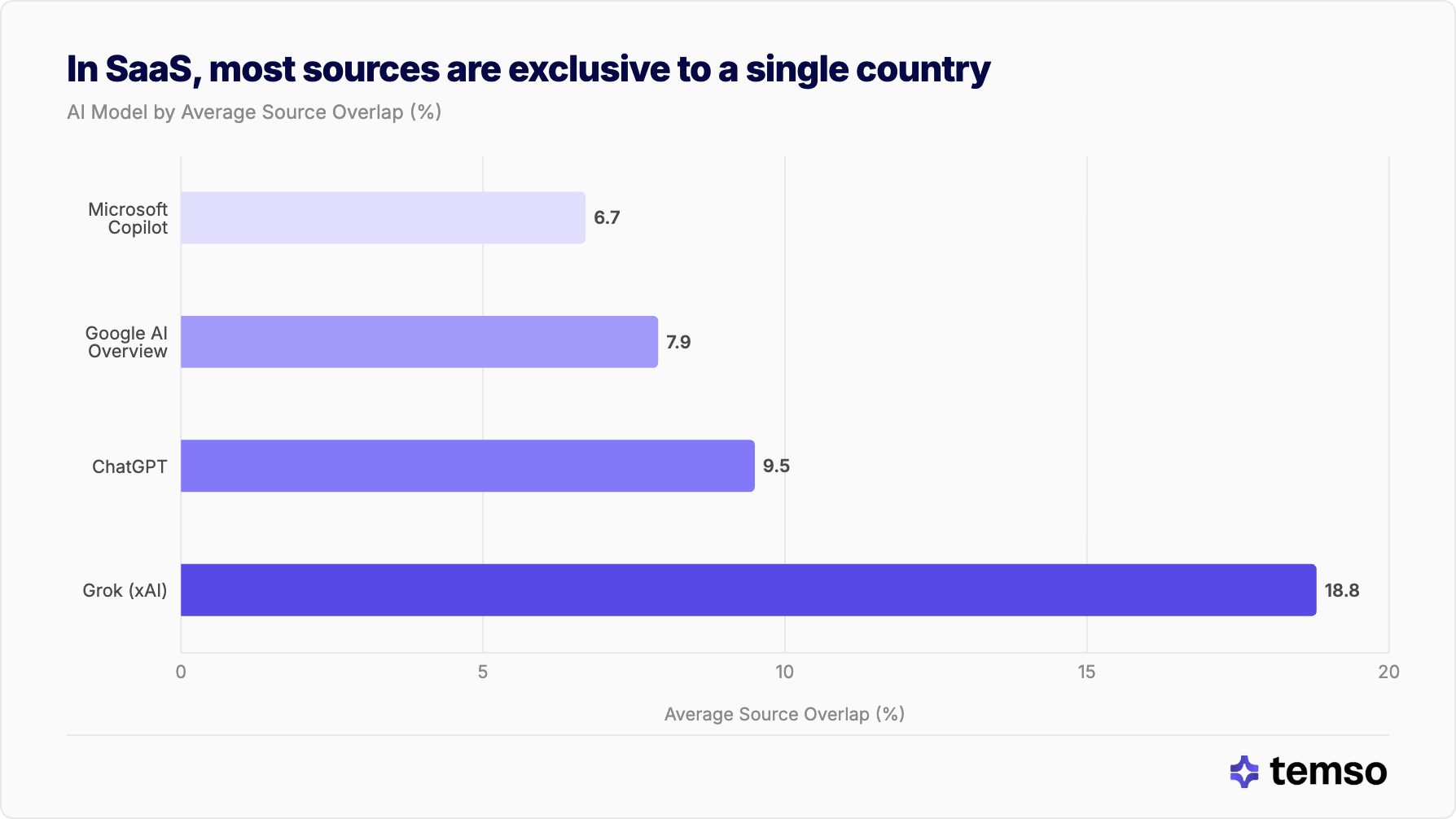
Los productos son globales. Las fuentes que los modelos de IA citan para hablar de ellos no lo son.
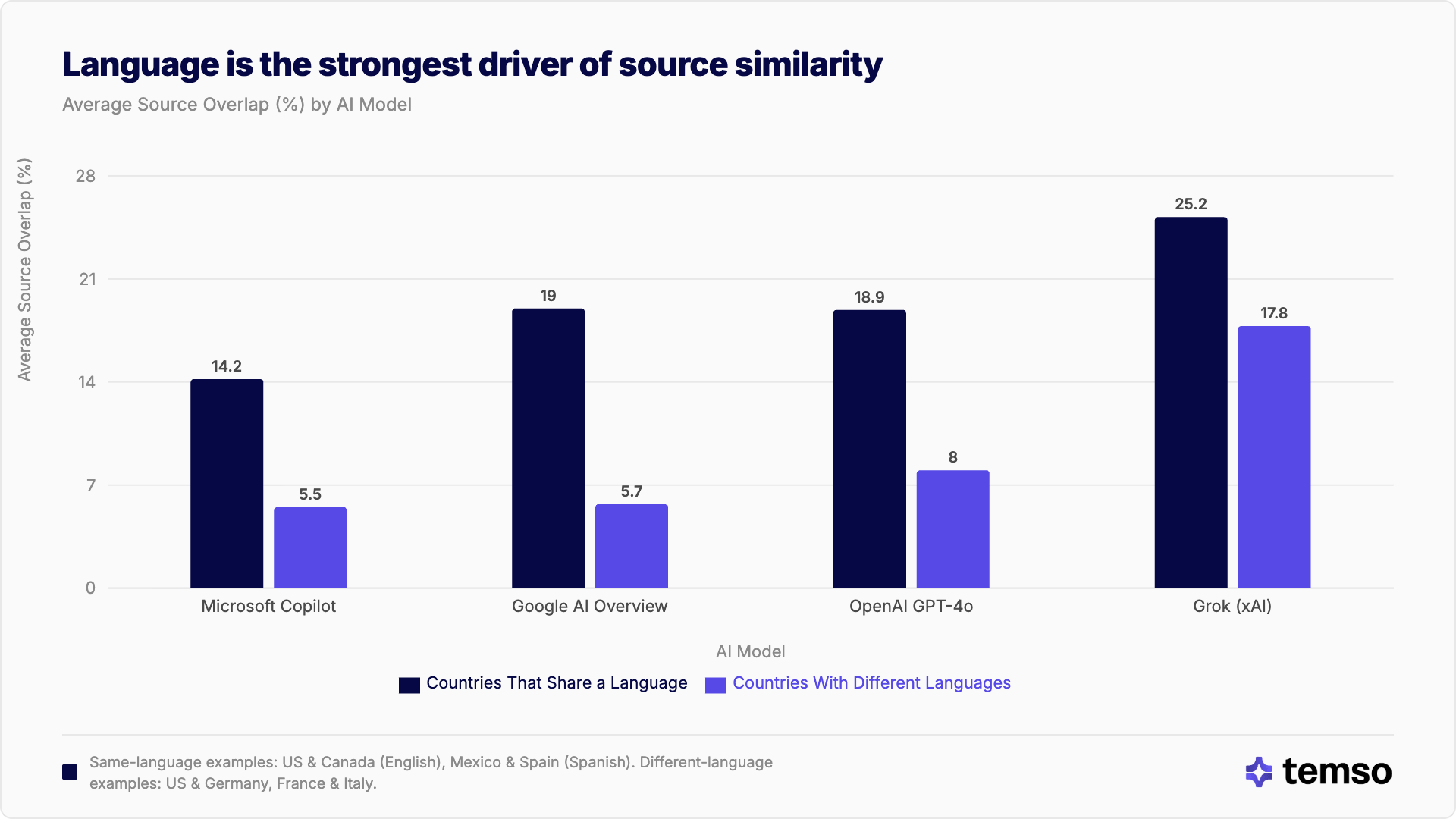
El idioma es el factor más determinante de la localización del SaaS en la búsqueda con IA
Los países que comparten idioma muestran muchísima más coincidencia de fuentes que los que no lo comparten. Los pares del mismo idioma comparten aproximadamente entre 1 de cada 4 y 1 de cada 7 dominios de origen de software, mientras que los pares de idiomas distintos caen a entre 1 de cada 6 y 1 de cada 18.
| Modelo | Coincidencia mismo idioma | Coincidencia idiomas distintos |
|---|---|---|
| Microsoft Copilot | 14,2 % | 5,5 |
| Google AI Overview | 19,0 % | 5,7 % |
| ChatGPT | 18,9 % | 8,0 % |
| Grok (xAI) | 25,2 % | 17,8 % |
Todos los tamaños del efecto son extremadamente grandes (d de Cohen > 3,3), lo que confirma que el idioma es, por sí solo, el predictor más potente de si dos países compartirán fuentes de software de IA. Esto se cumple incluso en el software, una categoría en la que la documentación y las reseñas en inglés dominan a nivel global.
¿Qué pares de países comparten más fuentes en ChatGPT?
| Par | Coincidencia de fuentes | Idioma |
|---|---|---|
| Canadá - EE. UU. | 23,9 % | Inglés |
| Argentina – España | 19,8 % | Español |
| Australia – Canadá | 19,0 % | Inglés |
| Argentina – México | 18,8 % | Español |
| Australia – EE. UU. | 18,4 % | Inglés |
| España – México | 17,9 % | Español |
| Reino Unido – EE. UU. | 17,8 % | Inglés |
| Canadá – Reino Unido | 17,5 % | Inglés |
| Australia – Reino Unido | 17,3 % | Inglés |
Canadá y EE. UU. encabezan la lista con un 23,9 % de coincidencia, la más alta de cualquier par del estudio. Tanto la proximidad como el idioma compartido contribuyen. Pero incluso en este mejor de los casos, cuando un canadiense y un estadounidense preguntan por el mismo software de CRM, tres cuartas partes de las fuentes citadas son diferentes.
Los pares de habla inglesa y los de habla hispana rinden de forma similar, agrupándose entre el 17 % y el 24 %. El mínimo de los pares del mismo idioma (Australia–Reino Unido, con un 17,3 %) sigue siendo más del doble de la coincidencia media entre idiomas distintos.
Francia es el mercado más aislado en ChatGPT
No todos los países están igual de desconectados. Francia destaca como el mercado con las fuentes más aisladas del estudio, ya que comparte la menor cantidad de dominios con cualquier otro país.
Los 5 pares con menor coincidencia (ChatGPT)
| Par | Coincidencia de fuentes |
|---|---|
| Francia – Suecia | 3,6 % |
| Francia – Canadá | 4,1 % |
| Francia – Italia | 4,7 % |
| Francia – Países Bajos | 4,7 % |
| Francia – Argentina | 4,9 % |
Francia aparece en los cinco pares con menor coincidencia. Su coincidencia media con otros países es aproximadamente la mitad de la media general. Esto refleja la fortaleza del ecosistema web en francés. Los modelos de IA franceses se nutren en gran medida de dominios .fr y de contenido en francés, lo que crea un conjunto de fuentes con una coincidencia mínima con cualquier otro mercado.
En el otro extremo del espectro, Canadá, Australia y los Países Bajos tienden a aparecer como países "puente". Todos comparten fuentes por encima de la media con varios grupos lingüísticos, probablemente porque sus mercados están más expuestos al contenido en inglés.
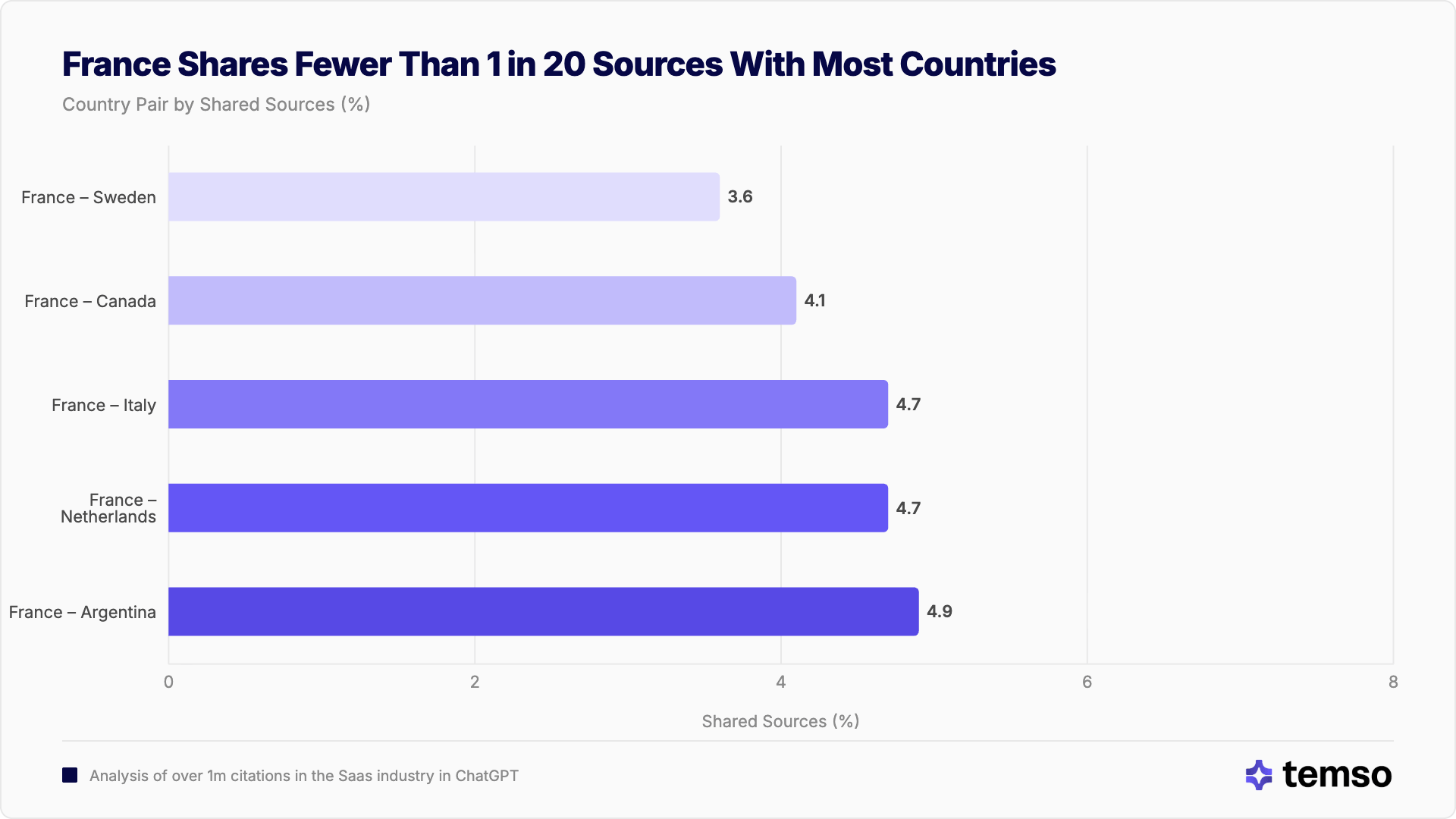
Francia comparte menos de 1 de cada 20 fuentes de software con la mayoría de los demás países, el aislamiento de fuentes más profundo del conjunto de datos.
Las regiones no se comportan como regiones
Muchas marcas globales organizan sus estrategias de IA y de contenido por región, por ejemplo "Europa del Sur", "mercados de habla inglesa", "América Latina". Los datos muestran que no todas las regiones son iguales. Algunas son agrupaciones de fuentes coherentes. Otras son un conjunto de mercados aislados que casualmente comparten una frontera.
Europa del Sur: tres países, tres ecosistemas de IA independientes
| Par | Fuentes compartidas |
|---|---|
| Francia – Italia | 4,7 % |
| Francia – España | 5,7 % |
| Italia – España | 9,8 % |
| Media regional | 6,7 % |
Francia, Italia y España comparten, en promedio, el 6,7 % de sus fuentes de software citadas por la IA. Menos de 1 de cada 15 dominios en común. Son países vecinos con idiomas estrechamente relacionados, marcos regulatorios comunes de la UE y economías profundamente entrelazadas. En cualquier otro contexto, agruparlos tiene sentido. En la visibilidad de fuentes de IA, no.
Cada país ha construido una capa profunda de contenido local (el 39 % de las fuentes de Francia están en dominios .fr, el 35 % de las de Italia en .it, el 31 % de las de España en .es) y esos dominios locales son invisibles en los otros dos mercados.
Compara eso con los mercados de habla inglesa
| Par | Fuentes compartidas |
|---|---|
| Canadá – EE. UU. | 23,9 % |
| Australia – Canadá | 19,0 % |
| Australia – EE. UU. | 18,4 % |
| Reino Unido – EE. UU. | 17,8 % |
| Canadá – Reino Unido | 17,5 % |
| Australia – Reino Unido | 17,3 % |
| Media regional | 19,0 % |
Los países de habla inglesa promedian un 19,0 % de fuentes compartidas. Eso es casi 3x la media de Europa del Sur. Aquí una estrategia regional sí tiene algún fundamento. No porque la geografía los conecte, sino porque un idioma compartido crea un conjunto de fuentes compartido.
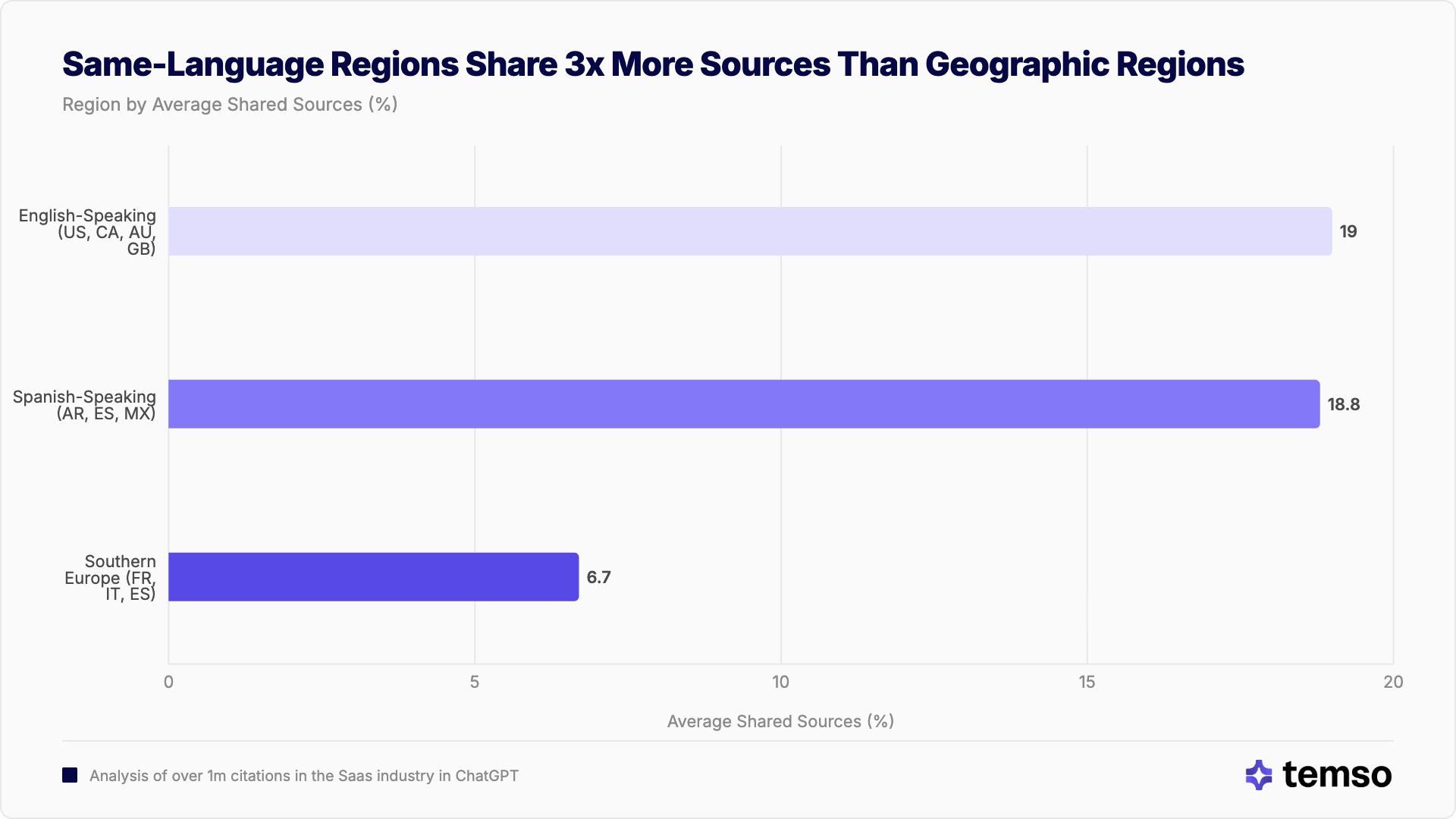
Cada modelo tiene una definición distinta de "local"
Los cuatro modelos de IA analizados muestran un rango constante pero drástico en lo agresivamente que localizan las fuentes.
Clasificación de localización (primero el más localizado):
- Microsoft Copilot: 6,7 % de coincidencia media (las fuentes más específicas por país)
- Google AI Overview: 7,9 %
- ChatGPT: 9,5 %
- Grok (xAI): 18,8 % (el más global, 2,8x más coincidencia que Copilot)
La brecha entre Copilot y Grok es estadísticamente enorme (d de Cohen = 3,29). El mismo prompt, los mismos países, los mismos productos de software, y aun así estos dos modelos se nutren de conjuntos de fuentes fundamentalmente distintos. Grok produce aproximadamente 8x más citas de fuentes por respuesta y extrae de un conjunto de dominios bastante más global.
Esto tiene consecuencias prácticas. Un dominio que ocupa una posición alta en el conjunto de fuentes de Grok puede ser invisible para Copilot, y viceversa. Las estrategias de visibilidad multimodelo deben tener en cuenta estas diferencias de arquitectura.
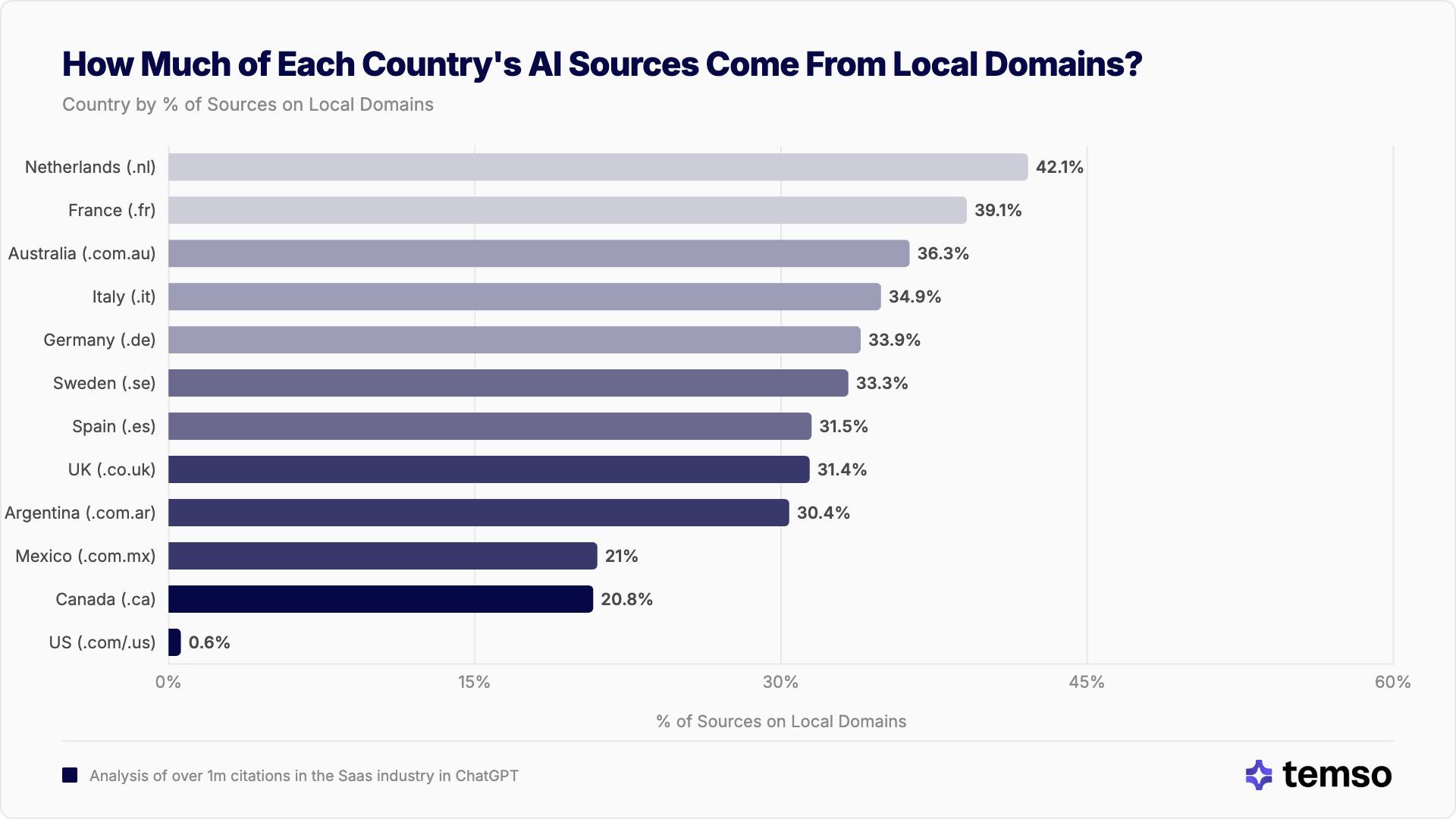
El .com domina las fuentes de software, pero los dominios locales siguen importando
Para el software global, .com es la extensión de dominio dominante en la mayoría de los mercados. Pero el grado de dominio del .com varía drásticamente según el país, y los dominios locales de código de país (.de, .nl, .se, .fr) siguen representando una parte significativa de las citas en muchos mercados.
Proporción de .com por país
| País | Proporción de .com |
|---|---|
| EE. UU. | 79,5 % |
| Canadá | 62,3 % |
| México | 59,4 % |
| Argentina | 55,4 % |
| Suecia | 55,0 % |
| España | 54,3 % |
| Reino Unido | 54,1 % |
| Australia | 50,6 % |
| Italia | 49,4 % |
| Alemania | 49,1 % |
| Países Bajos | 45,8 % |
| Francia | 44,5 % |
El .com es la fuente mayoritaria en 10 de 12 países. Solo Francia y los Países Bajos se mantienen por debajo del 50 %. Esto refleja la realidad de que la mayor parte del contenido de software empresarial, incluidos los sitios de proveedores, las plataformas de reseñas y los artículos comparativos, vive en dominios .com.
Proporción del dominio local de código de país de dos letras (ccTLD) por país
| País | Proporción de ccTLD local |
|---|---|
| Países Bajos (.nl) | 42,1 % |
| Francia (.fr) | 39,1 % |
| Australia (.com.au) | 36,3 % |
| Italia (.it) | 34,9 % |
| Alemania (.de) | 33,9 % |
| Suecia (.se) | 33,3 % |
| España (.es) | 31,5 % |
| Reino Unido (.co.uk) | 31,4 % |
| Argentina (.com.ar) | 30,4 % |
| México (.com.mx) | 21,0 % |
| Canadá (.ca) | 20,8 % |
| EE. UU. (.com/.us) | 0,6 % |
Incluso en el software, los dominios locales representan entre el 21 % y el 42 % de las citas en los mercados fuera de EE. UU. Los Países Bajos encabezan la lista con un 42,1 %, lo que significa que casi la mitad de todas las fuentes de software citadas a usuarios neerlandeses viven en dominios .nl. Esto resulta llamativo para un tema global y explica por qué la coincidencia de fuentes entre fronteras sigue siendo tan baja. Los modelos de IA de cada país se nutren de un conjunto profundo de contenido en el idioma local y en dominios locales que sencillamente no aparece en otros mercados.
Incluso para el software global, los dominios locales representan hasta el 42 % de las citas de IA, una capa oculta de la web que no cruza fronteras.
El panorama completo: coincidencia de fuentes país por país
El mapa de calor a continuación muestra la coincidencia de fuentes por pares entre los 12 países para ChatGPT en prompts de software. Las agrupaciones por idioma se ven con claridad: bloques cálidos para los países de habla inglesa (AU, CA, GB, US) y de habla hispana (AR, ES, MX), rodeados por celdas más frías de coincidencia entre idiomas distintos.
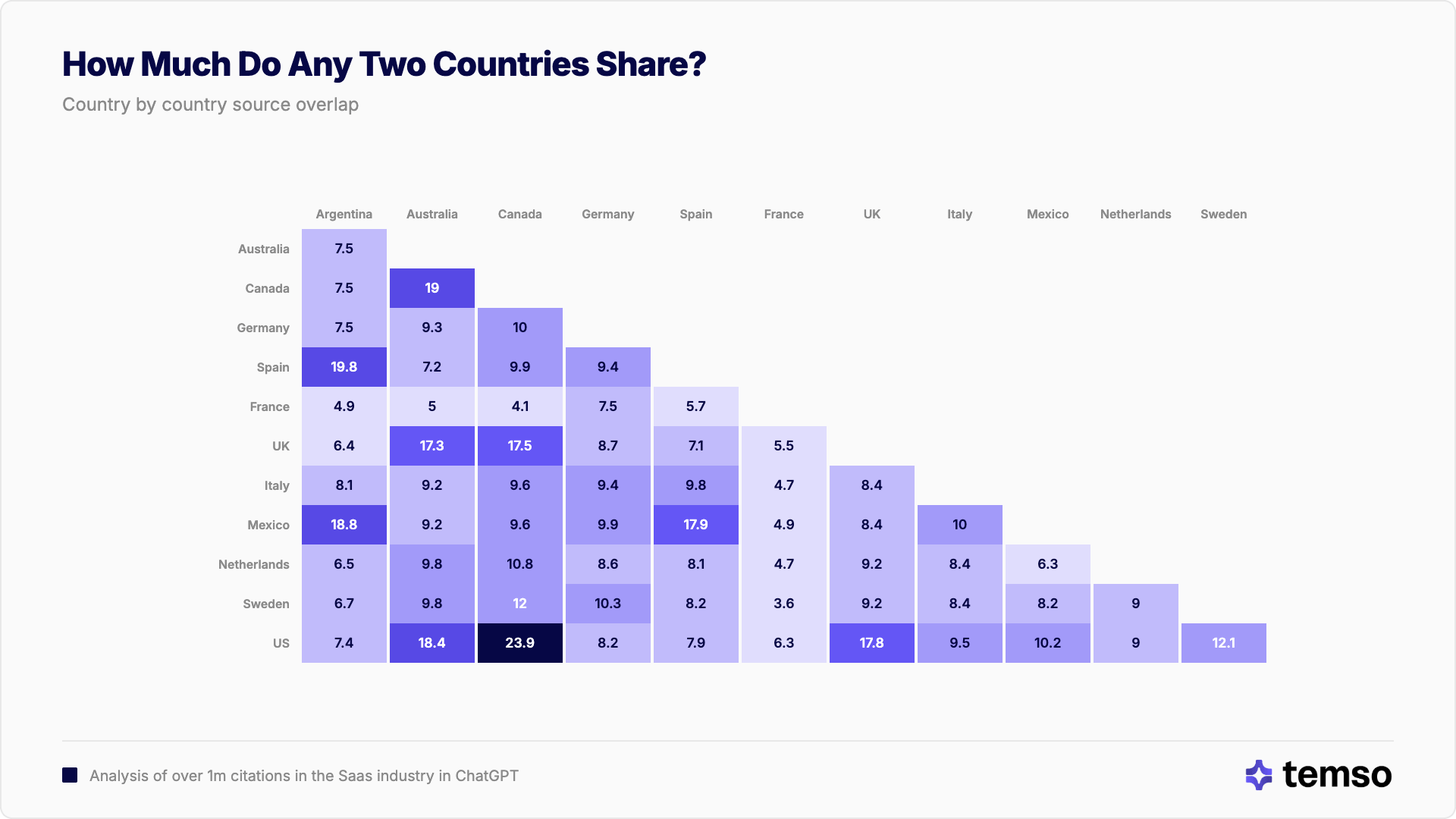
El mapa de calor revela una estructura por capas: las islas de idioma se asientan dentro de un mar más frío de coincidencia entre idiomas distintos. Francia (FR) es de forma constante la fila más fría, sus fuentes son las más aisladas de cualquier otro mercado. Alemania, Italia, los Países Bajos y Suecia ocupan una banda intermedia, compartiendo más entre sí (entre el 8 % y el 10 %) que con mercados lingüísticamente distantes, pero mucho menos que los pares del mismo idioma.
Metodología del estudio
Seleccionamos seis grupos de prompts de software y tecnología que cubren temas inherentemente globales: CRM, ciberseguridad, automatización de marketing, análisis de datos, herramientas de colaboración y agentes de IA. Ningún prompt de estos grupos hace referencia a una ubicación específica. Esto garantiza que cualquier divergencia de fuentes refleje efectos a nivel de país y de idioma, no la naturaleza local del tema en sí. Utilizamos las potentes capacidades de monitorización de Temso AI para recopilar y analizar información de alta calidad.
Para cada modelo de IA, recopilamos el conjunto completo de dominios web únicos citados en las respuestas de cada país y, luego, medimos la coincidencia por pares mediante la similitud de Jaccard, que es el porcentaje de dominios compartidos sobre el total de dominios citados en cualquiera de los dos países. Lo calculamos para cada par de los 12 países y, después, comparamos los pares del mismo idioma con los pares de idiomas distintos para medir el efecto del idioma.
La significancia estadística se evaluó mediante la d de Cohen para los tamaños del efecto y con intervalos de confianza del 95 % en todas las estimaciones medias. Todas las comparaciones superan el umbral mínimo de tamaño de muestra de 30 pares por grupo.
