
Resumen ejecutivo
Haz una pregunta en neerlandés y podrías esperar que te devuelvan fuentes en neerlandés. En Google AI Overview, eso es exactamente lo que ocurre: el 81% de las fuentes citadas coincide con el idioma del prompt. En Grok pasa lo contrario: las fuentes en inglés (53,5%) superan a las neerlandesas (38,3%). La IA que elijas determina si tu web en idioma local llega a verse o no.
Este estudio analizó más de 7 millones de citas generadas por IA en cuatro grandes modelos, seis idiomas distintos del inglés y 47 sectores. Los resultados revelan una brecha de 34 puntos porcentuales entre el modelo más localizado (Google AI Overview, 85,4% de citas en idioma local) y el menos localizado (Grok, 51,7%). El patrón se mantiene en todos los idiomas analizados, pero las lenguas germánicas como el neerlandés y el sueco son las más perjudicadas, mientras que las lenguas romances como el español y el francés salen comparativamente mejor paradas.
Para las empresas que invierten en contenido multilingüe, las implicaciones son concretas. Las páginas en idioma local tienen aproximadamente el doble de probabilidades de ser citadas por Google AI Overview que por Grok. El sector también importa: verticales inherentemente locales como la educación primaria y secundaria (K-12) y los servicios de limpieza alcanzan un 77% de citas en idioma local, mientras que sectores de orientación global como los hoteles y la hostelería caen hasta apenas un 36%. Decidir dónde invertir en contenido en idiomas distintos del inglés depende no solo de tu audiencia, sino de qué plataformas de IA usa esa audiencia.
Datos destacados
- Brecha de 34 pp entre el mejor y el peor modelo a la hora de citar fuentes en idioma local. Google AI Overview cita fuentes en el idioma del prompt el 85% de las veces. Grok logra solo el 52%.
- El 53,5% de las fuentes que cita Grok para prompts en neerlandés están en inglés, superando a las fuentes en neerlandés (38,3%). Es el único modelo en el que el inglés supera al idioma local.
- Brecha de 41 pp entre los sectores más y menos localizados. La educación K-12 alcanza un 77% de citas en idioma local. Los hoteles y la hostelería, apenas un 36%.
- 7 millones de citas generadas por IA analizadas, que abarcan 350.000 respuestas, 4 modelos, 6 idiomas distintos del inglés, 12 países y 47 sectores.
- El 39,6% de las citas de Grok recurren por defecto al inglés en prompts que no están en inglés. Casi dos de cada cinco fuentes están en inglés, cuatro veces la tasa de Google, del 8,7%.
Google lidera, Grok se queda atrás: una brecha de 34 puntos en la coincidencia de idioma
Cuando un prompt está escrito en un idioma distinto del inglés, la proporción de fuentes citadas que realmente coinciden con ese idioma varía enormemente según el modelo.
| Modelo | Idioma local | % inglés | % otros |
|---|---|---|---|
| Google AI Overviews | 85,4% | 8,7% | 5,9% |
| Microsoft Copilot | 76,7% | 15,4% | 7,9% |
| ChatGPT | 70,2% | 23,7% | 6,1% |
| Grok | 51,7% | 39,6% | 8,7% |
Todas las diferencias por pares son estadísticamente significativas (p < 0,0001 en cada comparación). Google AI Overview muestra de forma consistente fuentes en el idioma del prompt. Grok recurre por defecto al inglés casi el 40% de las veces, independientemente del idioma del prompt.
El patrón sugiere una relación estructural entre la arquitectura de recuperación y la localización lingüística. Los modelos con una integración de búsqueda más estrecha (Google AI Overview y Microsoft Copilot) parecen ajustar la recuperación al idioma del prompt de forma más eficaz. Los modelos que se apoyan en una indexación web más amplia o en estrategias de citación generativa recurren con mayor frecuencia por defecto a la web en inglés..png&w=3840&q=99&dpl=dpl_87xTtJujZr62TFUPZCDoNGDKPfLi)
El neerlandés y el sueco son los más golpeados por el sesgo hacia el inglés
No todos los idiomas se ven afectados por igual. Al desglosar las tasas de citación en idioma local por idioma del prompt se observa que las lenguas germánicas (en particular el neerlandés y el sueco) sufren la mayor intrusión del inglés en todos los modelos.
| Idioma del prompt | Google AI Overview | Copilot | ChatGPT | Grok |
|---|---|---|---|---|
| Italiano | 89,9% | 76,5% | 73,8% | 54,0% |
| Alemán | 89,8% | 75,9% | 66,0% | 49,3% |
| Sueco | 85,1% | 60,4% | 57,4% | 47,1% |
| Español | 83,4% | 83,5% | 74,6% | 55,3% |
| Francés | 82,1% | 87,2% | 72,3% | 58,9% |
| Neerlandés | 81,2% | 66,4% | 62,2% | 38,3% |
El resultado más llamativo es el del neerlandés en Grok. Cuando Grok procesa prompts en neerlandés, cita más fuentes en inglés (53,5%) que en neerlandés (38,3%). El inglés se convierte en el idioma de citación dominante.
El sueco sigue un patrón similar. En Grok, los prompts en sueco reciben un 43,7% de fuentes en inglés frente a un 47,1% en sueco, casi a la par. En Google AI Overview, esos mismos prompts producen un 85,1% de fuentes en sueco.
La brecha entre Google y Grok en los prompts en sueco es de 38,0 puntos porcentuales (p < 0,0001, z = 135,3). En los prompts en neerlandés, la brecha se amplía hasta 42,9 puntos porcentuales (p < 0,0001, z = 148,3).
Las lenguas romances salen mejor paradas de forma consistente. El español logra más del 55% de citas en idioma local incluso en Grok, y alcanza el 83-84% tanto en Google como en Copilot. El francés rinde más en Copilot, con un 87,2%. La explicación más probable: el español y el francés tienen volúmenes de contenido web sustancialmente mayores que el sueco o el neerlandés, lo que da a los modelos más material en idioma local para mostrar.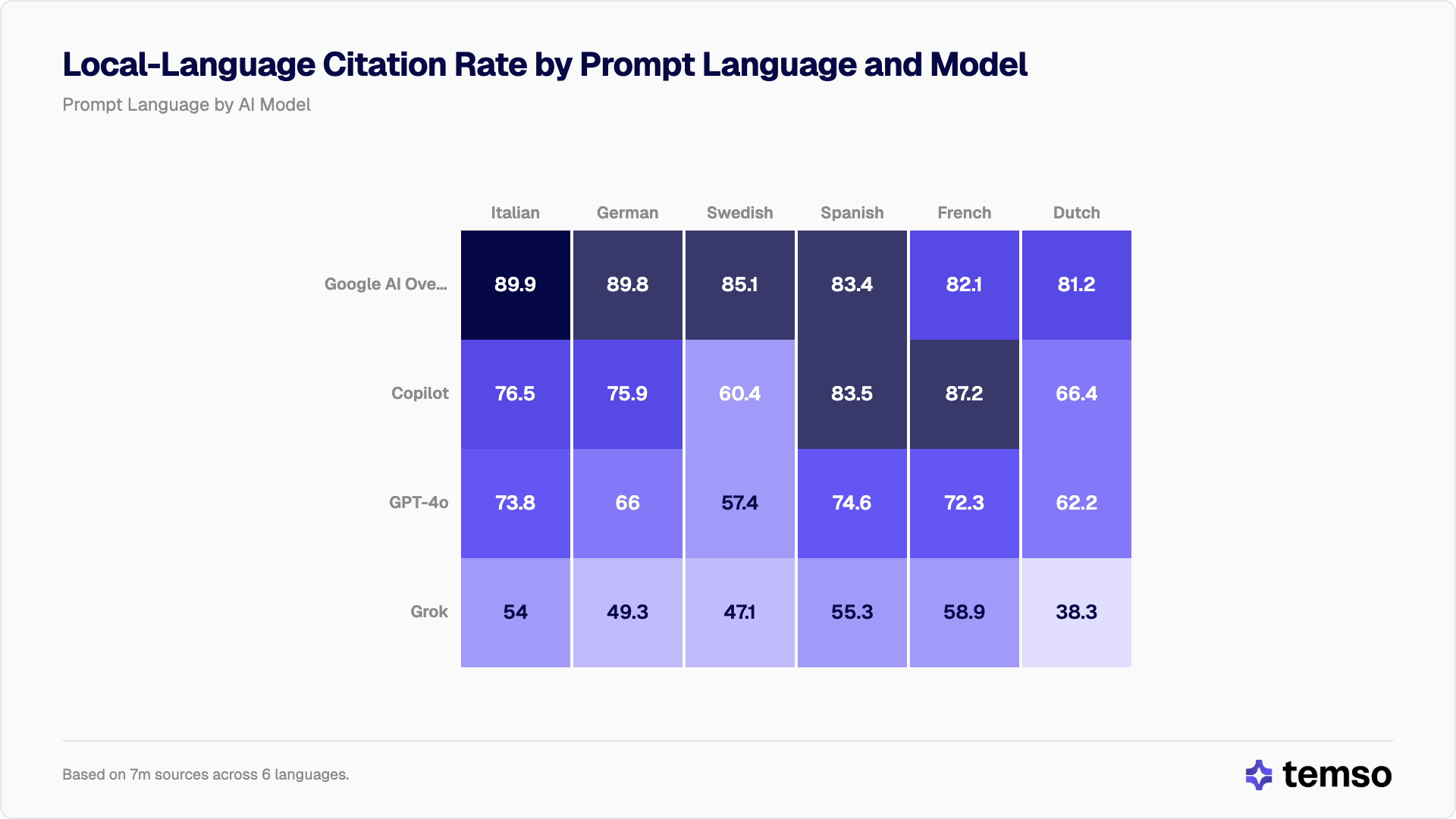
El sector importa tanto como la elección del modelo
La brecha entre los sectores más y menos localizados, 41 puntos porcentuales, es comparable en magnitud a la brecha entre el mejor y el peor modelo.
Mayor tasa de citas en idioma local (verticales inherentemente locales):
| Sector | % idioma local | % inglés |
|---|---|---|
| Educación K-12 | 76,9% | 12,3% |
| Servicios de limpieza | 73,3% | 17,4% |
| Educación en línea | 68,1% | 24,4% |
| Contabilidad y auditoría | 68,0% | 18,1% |
| Procesamiento de pagos | 67,9% | 27,4% |
| Reparación de vehículos | 65,3% | 23,9% |
Menor tasa de citas en idioma local (verticales de orientación global):
| Sector | % idioma local | % inglés |
|---|---|---|
| Hoteles y hostelería | 35,5% | 52,4% |
| Restaurantes y comidas | 38,9% | 46,3% |
| Agencias de diseño | 45,5% | 43,2% |
| Educación superior | 46,9% | 45,2% |
| Software de análisis de datos | 47,3% | 48,8% |
La diferencia entre la Educación K-12 (76,9%) y los Hoteles y hostelería (35,5%) es de 41,4 puntos porcentuales (p < 0,0001, z = 155,1).
El patrón es intuitivo. Los sectores con operaciones inherentemente locales (colegios, servicios de limpieza, mecánicos de coches, contables) generan contenido web en el idioma local porque sus clientes son locales. Los hoteles, las universidades de ranking internacional y las empresas de software producen más contenido en inglés porque operan a escala global. Los modelos de IA solo pueden citar lo que existe: cuando la presencia web de un sector es predominantemente en inglés, incluso el modelo mejor localizado tiene menos fuentes locales para mostrar.
.png&w=3840&q=99&dpl=dpl_87xTtJujZr62TFUPZCDoNGDKPfLi)
El efecto gravedad del inglés
Incluso en el modelo de mejor rendimiento, el inglés nunca desaparece del todo. En las cuatro plataformas, el inglés ejerce un tirón persistente sobre las citas, una fuerza gravitatoria de base que varía en intensidad pero que está siempre presente.
| Modelo | Tasa de citas en inglés (prompts no en inglés) |
|---|---|
| Google AI Overviews | 8,7% |
| Microsoft Copilot | 15,4% |
| ChatGPT | 23,7% |
| Grok | 39,6% |
Se estima que internet contiene aproximadamente un 60% de contenido en inglés. Frente a esa referencia, la tasa de citas en inglés del 8,7% de Google AI Overview para prompts no en inglés representa una contraindexación activa. Esto probablemente significa que el modelo prioriza de forma deliberada los resultados en idioma local. El 39,6% de Grok se sitúa más cerca de lo que cabría esperar de un sistema de recuperación ajeno al idioma que extrae contenido de la web al azar.
La implicación práctica para la estrategia de contenido: el contenido en idioma local tiene el mayor ROI de citación en Google AI Overview, donde el modelo lo busca activamente. En Grok, incluso el contenido en idioma local bien optimizado compite con un amplio conjunto de alternativas en inglés que el modelo trata como igualmente relevantes.
.png&w=3840&q=99&dpl=dpl_87xTtJujZr62TFUPZCDoNGDKPfLi)
Contexto
Este análisis parte de Temso AI, una plataforma de answer engine optimization que rastrea cómo aparecen las marcas en las respuestas generadas por IA. La plataforma envía prompts de orientación comercial (como "Best cybersecurity software in the US" o "Bästa försäkringsbolag i Sverige") a varios modelos de IA y registra la respuesta completa, incluidas todas las fuentes citadas.
El conjunto de datos abarca 7.058.891 citas individuales de fuentes en cuatro modelos: OpenAI ChatGPT, Microsoft Copilot, Grok y Google AI Overview. Los prompts se emitieron en siete idiomas (inglés, español, neerlandés, alemán, sueco, italiano y francés).
Estos hallazgos son más relevantes para las empresas con estrategias de contenido multilingüe, los equipos de SEO internacional y cualquiera que cree contenido pensado para que los sistemas de IA lo muestren en mercados no anglófonos. El conjunto de prompts tiene orientación comercial.
Metodología
Cada respuesta de IA contiene una lista de URL de fuentes citadas. Cotejamos cada URL citada con el idioma detectado de su página y luego comparamos ese idioma con el del prompt original. Esto generó un conjunto de datos de más de 4 millones de pares idioma-fuente / idioma-prompt solo para los prompts no en inglés.
Para cada combinación de modelo e idioma de prompt, calculamos la proporción de citas en las que el idioma de la página coincidía con el del prompt ("tasa de citas en idioma local"), la proporción que citaba páginas en inglés y el resto. Después repetimos este análisis por sector, usando el enfoque temático de cada proyecto de monitorización como aproximación del sector.
Todas las proporciones se contrastaron mediante pruebas z de dos proporciones con intervalos de confianza de puntuación de Wilson al nivel del 95%. Las diferencias entre modelos se validaron con pruebas chi-cuadrado de bondad de ajuste.
