
Resumo executivo
Faça uma pergunta em holandês e você provavelmente esperaria receber fontes em holandês. No Google AI Overview, é exatamente isso que acontece: 81% das fontes citadas correspondem ao idioma do prompt. No Grok, ocorre o oposto: fontes em inglês (53,5%) superam as holandesas (38,3%). A IA que você escolhe determina se a web em idioma local sequer aparece nos resultados.
Este estudo analisou mais de 7 milhões de citações geradas por IA em quatro modelos principais, seis idiomas não ingleses e 47 setores. Os resultados revelam uma diferença de 34 pontos percentuais entre o modelo mais localizado (Google AI Overview, 85,4% de citações em idioma local) e o menos localizado (Grok, 51,7%). O padrão se repete em todos os idiomas testados, mas as línguas germânicas como o holandês e o sueco sofrem mais, enquanto as línguas românicas como o espanhol e o francês saem comparativamente melhor.
Para empresas que investem em conteúdo multilíngue, as implicações são concretas. Páginas em idioma local têm aproximadamente o dobro de chance de ser citadas pelo Google AI Overview do que pelo Grok. O setor também importa: verticais com operações inerentemente locais, como educação K-12 e serviços de limpeza, atingem 77% de citações em idioma local, enquanto setores com atuação global, como hotéis e hotelaria, caem para apenas 36%. A decisão de onde investir em conteúdo não inglês depende não só da sua audiência, mas também de quais plataformas de IA ela usa.
Destaques
- Diferença de 34 pp entre o melhor e o pior modelo na citação de fontes em idioma local. O Google AI Overview cita fontes no idioma do prompt 85% das vezes. O Grok alcança apenas 52%.
- 53,5% das fontes que o Grok cita para prompts em holandês estão em inglês, superando as fontes em holandês (38,3%). É o único modelo em que o inglês ultrapassa o idioma local.
- Diferença de 41 pp entre os setores mais e menos localizados. A educação K-12 tem 77% de citações em idioma local. Hotéis e hotelaria chegam a apenas 36%.
- 7 milhões de citações geradas por IA analisadas, abrangendo 350.000 respostas, 4 modelos, 6 idiomas não ingleses, 12 países e 47 setores.
- 39,6% das citações do Grok recorrem ao inglês em prompts não ingleses. Quase duas em cada cinco fontes estão em inglês, quatro vezes a taxa do Google, de 8,7%.
Google lidera, Grok fica para trás: diferença de 34 pontos na correspondência de idioma
Quando um prompt é escrito em um idioma não inglês, a proporção de fontes citadas que realmente correspondem a esse idioma varia enormemente de acordo com o modelo.
| Modelo | Idioma local | % inglês | % outros |
|---|---|---|---|
| Google AI Overviews | 85,4% | 8,7% | 5,9% |
| Microsoft Copilot | 76,7% | 15,4% | 7,9% |
| ChatGPT | 70,2% | 23,7% | 6,1% |
| Grok | 51,7% | 39,6% | 8,7% |
Todas as diferenças entre pares são estatisticamente significativas (p < 0,0001 em cada comparação). O Google AI Overview apresenta consistentemente fontes no idioma do prompt. O Grok recorre ao inglês em quase 40% das vezes, independentemente do idioma do prompt.
O padrão sugere uma relação estrutural entre a arquitetura de recuperação e a localização linguística. Modelos com integração de busca mais estreita (Google AI Overview e Microsoft Copilot) parecem ajustar a recuperação ao idioma do prompt com mais eficiência. Modelos que dependem de indexação web mais ampla ou de estratégias de citação generativa recorrem com mais frequência à web em inglês..png&w=3840&q=99&dpl=dpl_87xTtJujZr62TFUPZCDoNGDKPfLi)
Holandês e sueco são os mais afetados pelo viés ao inglês
Nem todos os idiomas são impactados da mesma forma. Ao detalhar as taxas de citação em idioma local por idioma do prompt, fica claro que as línguas germânicas (holandês e sueco em particular) sofrem a maior intrusão do inglês em todos os modelos.
| Idioma do prompt | Google AI Overview | Copilot | ChatGPT | Grok |
|---|---|---|---|---|
| Italiano | 89,9% | 76,5% | 73,8% | 54,0% |
| Alemão | 89,8% | 75,9% | 66,0% | 49,3% |
| Sueco | 85,1% | 60,4% | 57,4% | 47,1% |
| Espanhol | 83,4% | 83,5% | 74,6% | 55,3% |
| Francês | 82,1% | 87,2% | 72,3% | 58,9% |
| Holandês | 81,2% | 66,4% | 62,2% | 38,3% |
O resultado mais chamativo é o do holandês no Grok. Quando o Grok processa prompts em holandês, cita mais fontes em inglês (53,5%) do que em holandês (38,3%). O inglês se torna o idioma de citação dominante.
O sueco segue um padrão semelhante. No Grok, prompts em sueco recebem 43,7% de fontes em inglês contra 47,1% em sueco, quase empatados. No Google AI Overview, esses mesmos prompts geram 85,1% de fontes em sueco.
A diferença entre Google e Grok em prompts suecos é de 38,0 pontos percentuais (p < 0,0001, z = 135,3). Em prompts holandeses, essa diferença sobe para 42,9 pontos percentuais (p < 0,0001, z = 148,3).
As línguas românicas saem consistentemente melhor. O espanhol atinge mais de 55% de citações em idioma local mesmo no Grok, e chega a 83-84% tanto no Google quanto no Copilot. O francês tem o melhor desempenho no Copilot, com 87,2%. A explicação mais provável: espanhol e francês têm volumes de conteúdo web substancialmente maiores do que sueco ou holandês, dando aos modelos mais material em idioma local para apresentar.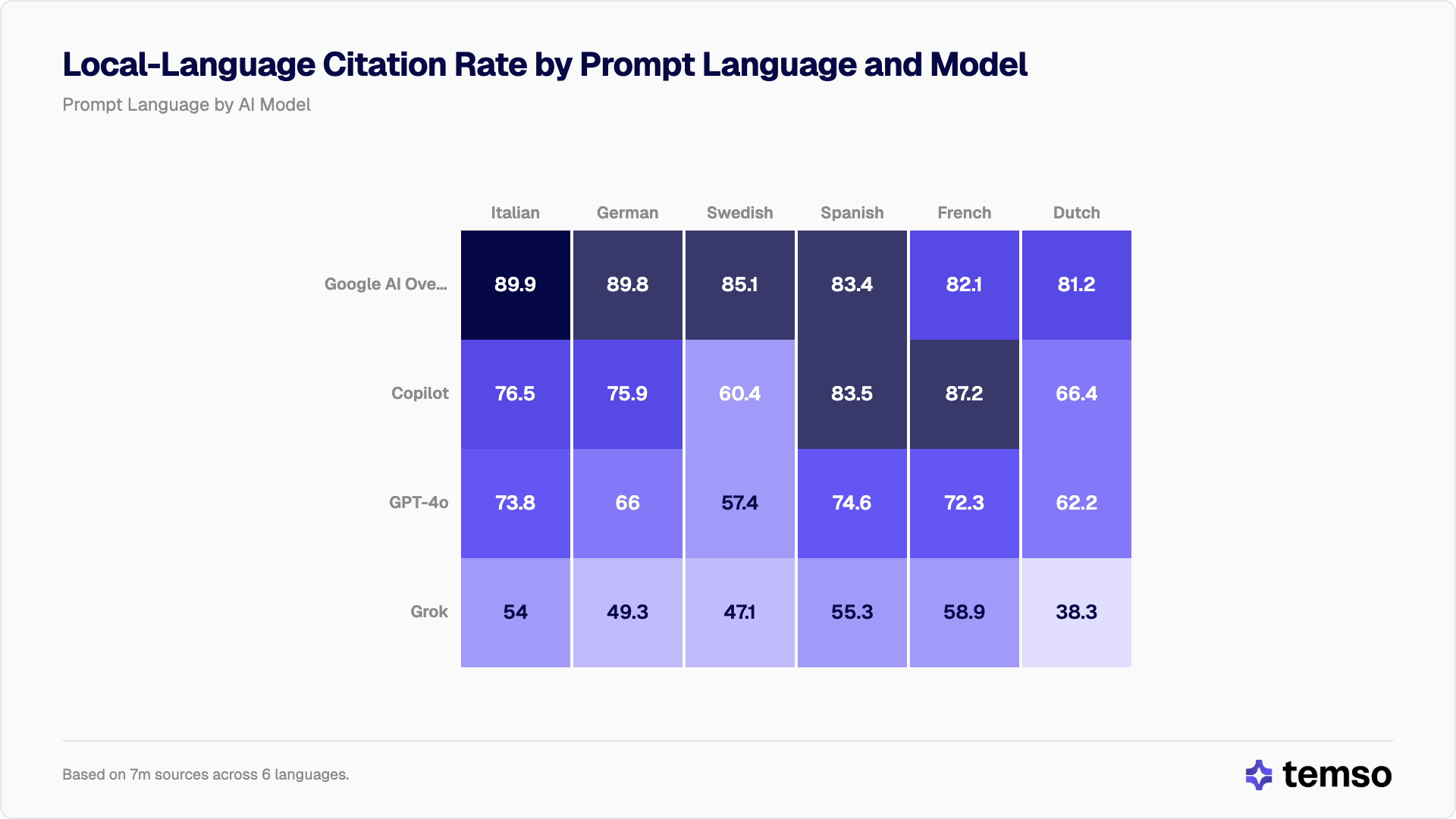
O setor importa tanto quanto a escolha do modelo
A diferença entre os setores mais e menos localizados, 41 pontos percentuais, é comparável em magnitude à diferença entre o melhor e o pior modelo.
Maior taxa de citações em idioma local (verticais inerentemente locais):
| Setor | % idioma local | % inglês |
|---|---|---|
| Educação K-12 | 76,9% | 12,3% |
| Serviços de limpeza | 73,3% | 17,4% |
| Educação online | 68,1% | 24,4% |
| Contabilidade e auditoria | 68,0% | 18,1% |
| Processamento de pagamentos | 67,9% | 27,4% |
| Reparação de veículos | 65,3% | 23,9% |
Menor taxa de citações em idioma local (verticais com atuação global):
| Setor | % idioma local | % inglês |
|---|---|---|
| Hotéis e hotelaria | 35,5% | 52,4% |
| Restaurantes e alimentação | 38,9% | 46,3% |
| Agências de design | 45,5% | 43,2% |
| Ensino superior | 46,9% | 45,2% |
| Software de análise de dados | 47,3% | 48,8% |
A diferença entre Educação K-12 (76,9%) e Hotéis e hotelaria (35,5%) é de 41,4 pontos percentuais (p < 0,0001, z = 155,1).
O padrão é intuitivo. Setores com operações inerentemente locais (escolas, serviços de limpeza, mecânicos, contadores) geram conteúdo web em idioma local porque seus clientes são locais. Hotéis, universidades com rankings internacionais e empresas de software produzem mais conteúdo em inglês porque atuam globalmente. Modelos de IA só podem citar o que existe: quando a presença web de um setor é predominantemente em inglês, mesmo o modelo mais bem localizado tem menos fontes locais para apresentar.
.png&w=3840&q=99&dpl=dpl_87xTtJujZr62TFUPZCDoNGDKPfLi)
O efeito gravidade do inglês
Mesmo no modelo de melhor desempenho, o inglês nunca desaparece completamente. Em todas as quatro plataformas, o inglês exerce uma atração persistente sobre as citações, uma força gravitacional de base que varia em intensidade, mas está sempre presente.
| Modelo | Taxa de citações em inglês (prompts não ingleses) |
|---|---|
| Google AI Overviews | 8,7% |
| Microsoft Copilot | 15,4% |
| ChatGPT | 23,7% |
| Grok | 39,6% |
Estima-se que a internet contenha cerca de 60% de conteúdo em inglês. Diante desse cenário, a taxa de citações em inglês de 8,7% do Google AI Overview para prompts não ingleses representa uma contra-indexação ativa. Isso provavelmente significa que o modelo prioriza deliberadamente os resultados em idioma local. Os 39,6% do Grok ficam mais próximos do que se esperaria de um sistema de recuperação sem consciência de idioma, que simplesmente extrai conteúdo aleatoriamente da web.
A implicação prática para a estratégia de conteúdo: o conteúdo em idioma local tem o maior ROI de citação no Google AI Overview, onde o modelo o busca ativamente. No Grok, mesmo o conteúdo em idioma local bem otimizado compete com um grande conjunto de alternativas em inglês que o modelo trata como igualmente relevantes.
.png&w=3840&q=99&dpl=dpl_87xTtJujZr62TFUPZCDoNGDKPfLi)
Contexto
Esta análise parte do Temso AI, uma plataforma de answer engine optimization que rastreia como marcas aparecem nas respostas geradas por IA. A plataforma envia prompts de orientação comercial (como "Best cybersecurity software in the US" ou "Bästa försäkringsbolag i Sverige") a múltiplos modelos de IA e registra a resposta completa, incluindo todas as fontes citadas.
O conjunto de dados abrange 7.058.891 citações individuais de fontes em quatro modelos: OpenAI ChatGPT, Microsoft Copilot, Grok e Google AI Overview. Os prompts foram enviados em sete idiomas (inglês, espanhol, holandês, alemão, sueco, italiano e francês).
Esses resultados são mais relevantes para empresas com estratégias de conteúdo multilíngue, equipes de SEO internacional e qualquer pessoa que produza conteúdo voltado para ser exibido por sistemas de IA em mercados não anglófonos. O conjunto de prompts tem orientação comercial.
Metodologia
Cada resposta de IA contém uma lista de URLs de fontes citadas. Cruzamos cada URL citada com o idioma detectado da página e depois comparamos esse idioma com o do prompt original. Isso gerou um conjunto de dados com mais de 4 milhões de pares idioma-fonte / idioma-prompt apenas para os prompts não ingleses.
Para cada combinação de modelo e idioma de prompt, calculamos a proporção de citações em que o idioma da página correspondia ao do prompt ("taxa de citações em idioma local"), a proporção que citava páginas em inglês e o restante. Em seguida, repetimos essa análise por setor, usando o foco temático de cada projeto de monitoramento como proxy do setor.
Todas as proporções foram testadas usando testes z de duas proporções com intervalos de confiança de escore de Wilson ao nível de 95%. As diferenças entre modelos foram validadas com testes qui-quadrado de aderência.
