
Executive summary
Ask a question in Dutch and you might expect Dutch-language sources in return. On Google AI Overview, that is exactly what happens — 81% of cited sources match the prompt language. On Grok, the opposite occurs: English sources (53.5%) outnumber Dutch ones (38.3%). The AI you choose determines whether your local-language web gets seen at all.
This study analyzed over 7 million AI-generated citations across four major models, six non-English languages, and 47 industry verticals. The results reveal a 34-percentage-point gap between the most localized model (Google AI Overview, 85.4% local-language citation) and the least (Grok, 51.7%). The pattern holds across every language tested — but Germanic languages like Dutch and Swedish suffer the most, while Romance languages like Spanish and French fare comparatively better.
For businesses investing in multilingual content, the implications are concrete. Local-language pages are roughly twice as likely to be cited by Google AI Overview as by Grok. Industry also matters: inherently local verticals like K-12 education and cleaning services see 77% local-language citation, while globally oriented industries like hotels and hospitality drop to just 36%. Choosing where to invest in non-English content depends not only on your audience, but on which AI platforms your audience uses.
Highlights
- The dataset: This study is an analysis of over 7 million AI source citations using prompts spanning 47 industries. It analyzes AI responses from four AI models run in 12 countries in early 2026.
- 41 pp gap between the most and least localized industries: K-12 education sees 77% local-language citations.
- The full sample: Over 7 million AI-generated citations analyzed, spanning 350,000 responses, 4 models, 6 non-English languages, 12 countries, and 47 industries.
- English outnumbers Dutch: 54% of sources Grok cites for Dutch-language prompts are in English, outnumbering Dutch sources (38%).
- 34 pp gap between the best and worst model: Google AI Overview cites sources in the prompt's language 85% of the time.
- 40% of Grok citations default to English on non-English prompts: Nearly two in five sources are in English, four times Google AI Overview's rate of 9%.
Google AI Overview leads, Grok lags: a 34-point gap in language matching
When a prompt is written in a non-English language, the share of cited sources that actually match that language varies enormously by model.
| Model | Local language | English % | Other % |
|---|---|---|---|
| Google AI Overviews | 85.4% | 8.7% | 5.9% |
| Microsoft Copilot | 76.7% | 15.4% | 7.9% |
| ChatGPT | 70.2% | 23.7% | 6.1% |
| Grok | 51.7% | 39.6% | 8.7% |
All pairwise differences are statistically significant (p < 0.0001 for every comparison). Google AI Overview consistently surfaces sources in the language of the prompt. Grok defaults to English nearly 40% of the time, regardless of the prompt language.
The pattern suggests a structural relationship between retrieval architecture and language localization. Models with tighter search integration (Google AI Overview and Microsoft Copilot) appear to match retrieval to the prompt's language more effectively. Models that rely on broader web indexing or generative citation strategies default more heavily to the English-language web..png&w=3840&q=99&dpl=dpl_5vYRDHkcy5hJgCphS3THPnhmsm3Y)
Dutch and Swedish hit hardest by English-language bias
Not all languages are affected equally. Breaking down local-language citation rates by prompt language reveals that Germanic languages (Dutch and Swedish in particular) suffer the largest English-language intrusion across all models.
| Prompt Language | Google AI Overview | Microsoft Copilot | ChatGPT | Grok |
|---|---|---|---|---|
| Italian | 89.9% | 76.5% | 73.8% | 54.0% |
| German | 89.8% | 75.9% | 66.0% | 49.3% |
| Swedish | 85.1% | 60.4% | 57.4% | 47.1% |
| Spanish | 83.4% | 83.5% | 74.6% | 55.3% |
| French | 82.1% | 87.2% | 72.3% | 58.9% |
| Dutch | 81.2% | 66.4% | 62.2% | 38.3% |
The most striking result is Dutch on Grok. When Grok processes Dutch-language prompts, it cites more English sources (53.5%) than Dutch sources (38.3%). English becomes the dominant citation language.
Swedish follows a similar pattern. On Grok, Swedish prompts receive 43.7% English sources versus 47.1% Swedish, nearly equal. On Google AI Overview, those same prompts produce 85.1% Swedish sources.
The gap between Google AI Overview and Grok on Swedish prompts is 38.0 percentage points (p < 0.0001, z = 135.3). On Dutch prompts, the gap widens to 42.9 percentage points (p < 0.0001, z = 148.3).
Romance languages consistently fare better. Spanish achieves above 55% local-language citation even on Grok, and reaches 83–84% on both Google AI Overview and Microsoft Copilot. French performs strongest on Microsoft Copilot at 87.2%. The likely explanation: Spanish and French have substantially larger volumes of web content than Swedish or Dutch, giving models more local-language material to surface.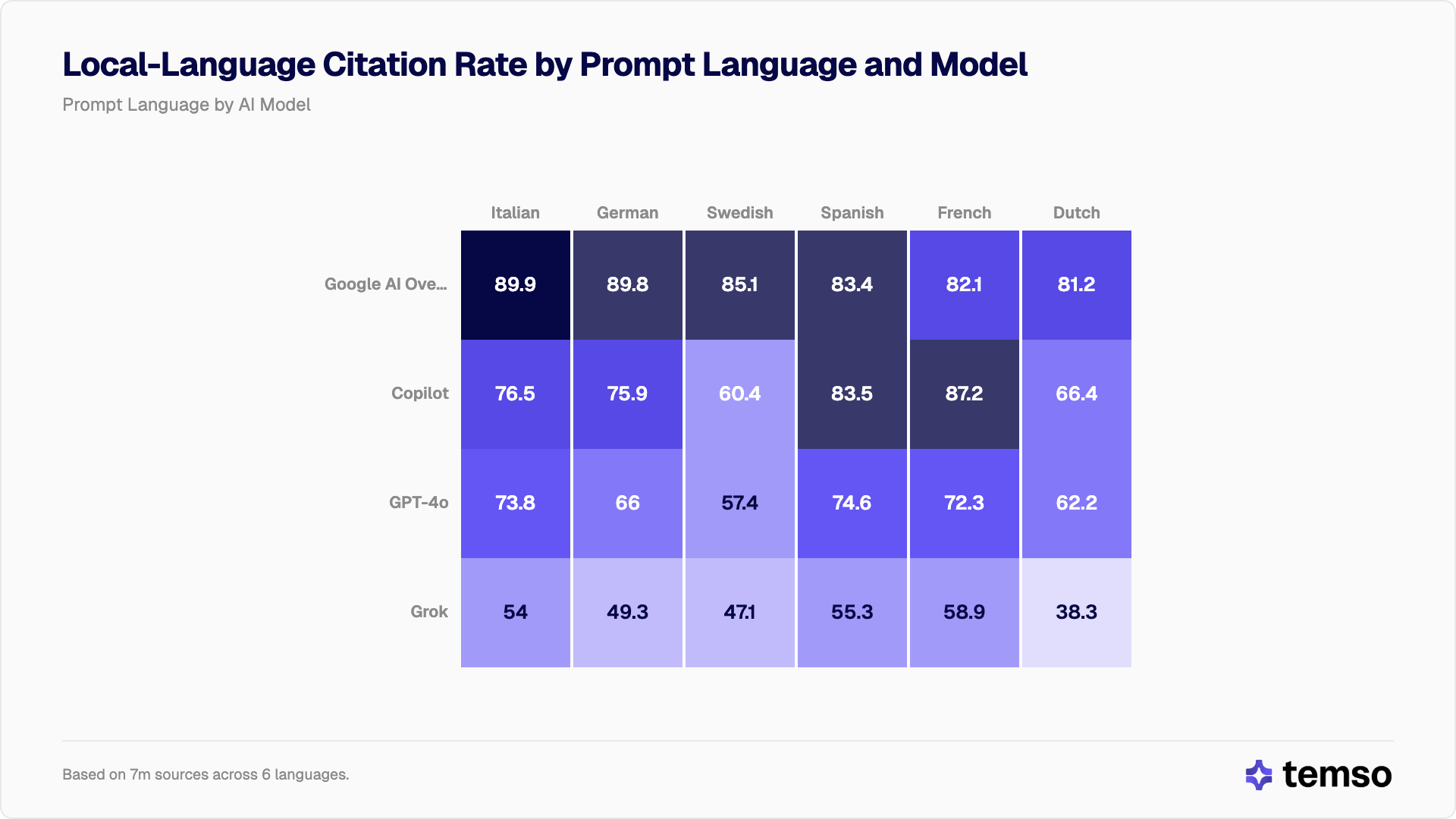
Industry matters as much as model choice
The gap between the most and least localized industries — 41 percentage points — is comparable in magnitude to the gap between the best and worst model.
Highest local-language citation (inherently local verticals):
| Industry | Local-Language % | English % |
|---|---|---|
| K-12 Education | 76.9% | 12.3% |
| Cleaning Services | 73.3% | 17.4% |
| Online Education | 68.1% | 24.4% |
| Accounting & Audit | 68.0% | 18.1% |
| Payment Processing | 67.9% | 27.4% |
| Auto Repair | 65.3% | 23.9% |
Lowest local-language citation (globally-oriented verticals):
| Industry | Local-Language % | English % |
|---|---|---|
| Hotels & Hospitality | 35.5% | 52.4% |
| Restaurants & Dining | 38.9% | 46.3% |
| Design Agencies | 45.5% | 43.2% |
| Higher Education | 46.9% | 45.2% |
| Data Analytics Software | 47.3% | 48.8% |
The difference between K-12 Education (76.9%) and Hotels & Hospitality (35.5%) is 41.4 percentage points (p < 0.0001, z = 155.1).
The pattern is intuitive. Industries with inherently local operations (schools, cleaning services, auto mechanics, accountants) generate web content in the local language because their customers are local. Hotels, internationally ranked universities, and software companies produce more English-language content because they operate globally. AI models can only cite what exists: when an industry's web presence is predominantly English, even the best-localized model has fewer local sources to surface.
.png&w=3840&q=99&dpl=dpl_5vYRDHkcy5hJgCphS3THPnhmsm3Y)
The English gravity effect
Even on the best-performing model, English never fully disappears. Across all four platforms, English exerts a persistent pull on citations a baseline gravitational force that varies in strength but is always present.
| Model | English Citation Rate (Non-English Prompts) |
|---|---|
| Google AI Overviews | 8.7% |
| Microsoft Copilot | 15.4% |
| ChatGPT | 23.7% |
| Grok | 39.6% |
The internet is estimated to be roughly 60% English-language content. Against that baseline, Google AI Overview's 8.7% English citation rate for non-English prompts represents active counter-indexing. This likely means the model is deliberately prioritizing local-language results. Grok's 39.6% sits closer to what you might expect from a language-unaware retrieval system drawing randomly from the web.
The practical implication for content strategy: local-language content has the highest citation ROI on Google AI Overview, where the model actively seeks it out. On Grok, even well-optimized local-language content competes with a large pool of English alternatives that the model treats as equally relevant.
.png&w=3840&q=99&dpl=dpl_5vYRDHkcy5hJgCphS3THPnhmsm3Y)
Context
This analysis draws from Temso AI, an answer engine optimization platform that tracks how brands appear in AI-generated responses. The platform sends commercially oriented prompts (such as "Best cybersecurity software in the US" or "Bästa försäkringsbolag i Sverige") to multiple AI models and records the full response, including all cited sources.
The dataset covers 7,058,891 individual source citations across four models: OpenAI ChatGPT, Microsoft Copilot, Grok, and Google AI Overview. Prompts were issued in seven languages (English, Spanish, Dutch, German, Swedish, Italian, and French).
These findings are most relevant to businesses with multilingual content strategies, international SEO teams, and anyone building content intended to be surfaced by AI systems in non-English markets. The prompt set is commercially oriented.
Methodology
Each AI response contains a list of cited source URLs. We matched every cited URL to its detected page language, then compared that language to the language of the original prompt. This produced a dataset of over 4 million source-to-prompt language pairs for non-English prompts alone.
For each model and prompt language combination, we calculated the proportion of citations where the page language matched the prompt language ("local-language citation rate"), the proportion citing English-language pages, and the remainder. We then repeated this analysis by industry vertical, using the thematic focus of each monitoring project as a proxy for industry.
All proportions were tested using two-proportion z-tests with Wilson score confidence intervals at the 95% level. Cross-model differences were validated with chi-square goodness-of-fit tests.
