
Resumen ejecutivo
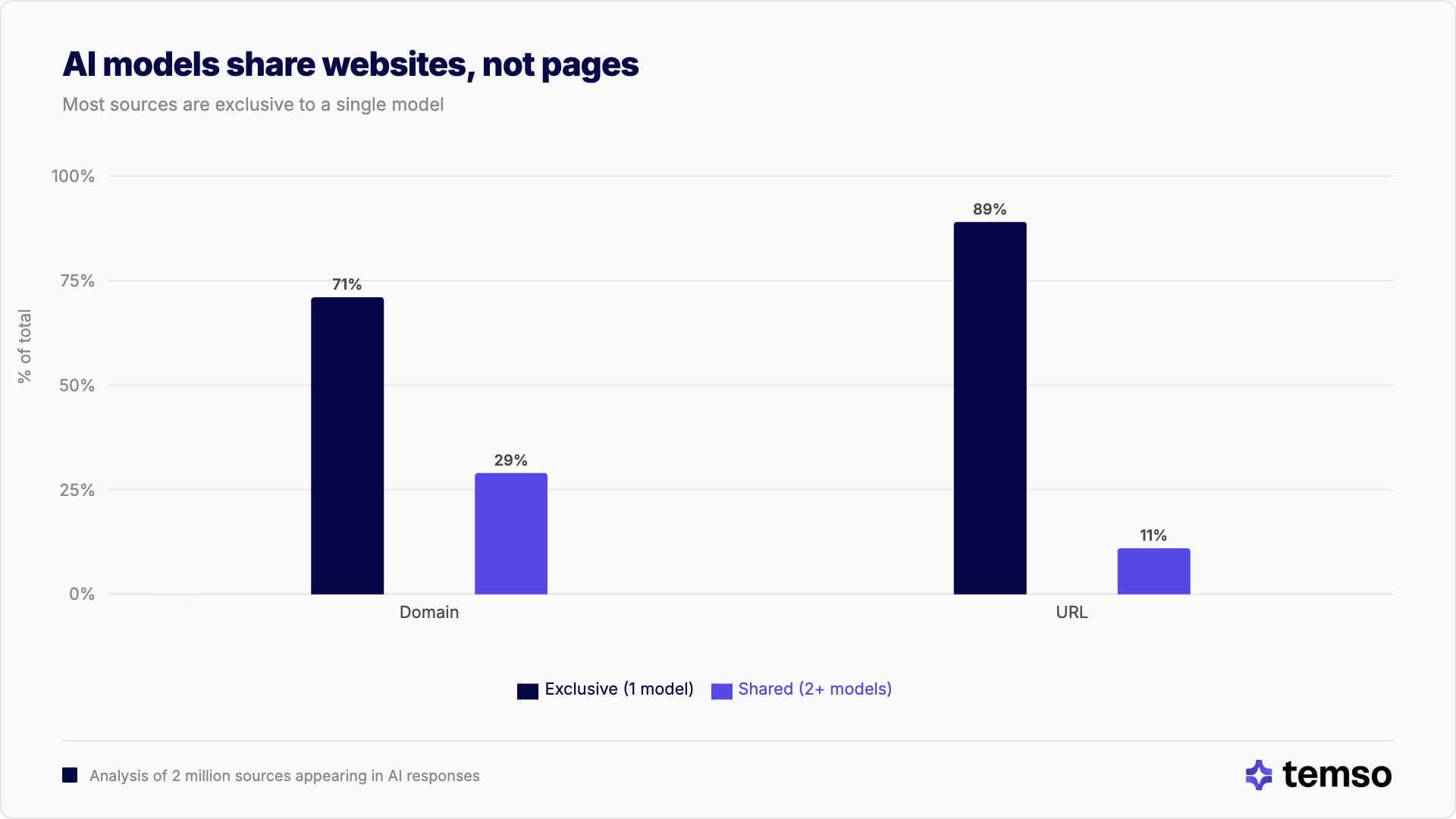
Cada modelo de IA vive en su propio universo de citas. Cuando enviamos los mismos prompts a ChatGPT, Google AI Overview, Gemini, Grok y Copilot, y analizamos más de 2 millones de fuentes citadas, el 71% de los sitios web que citaron aparecieron en las respuestas de un solo modelo. A nivel de página específica, la fragmentación es aún más marcada: el 89% de las URL son exclusivas de un único modelo.
El par promedio de modelos de IA comparte apenas el 14.4% de sus dominios citados. Incluso los dos modelos con mayor solapamiento (AI Overview y Grok) coinciden en solo 1 de cada 5 fuentes. ChatGPT y AI Overview, las dos plataformas más usadas, comparten menos de 1 de cada 5 dominios. Grok resultó ser el modelo con la huella de fuentes más amplia y singular. Gemini se sitúa en el extremo opuesto, con más del 80% de sus citas provenientes de dominios que al menos otro modelo ya referencia.
Para las marcas y publicaciones que gestionan su visibilidad en IA, la implicación es directa: una fuente que rinde bien en una plataforma puede ser invisible en otra. Cada modelo extrae de su propia porción distinta de la web, y una estrategia de optimización para una sola plataforma deja puntos ciegos significativos.
Puntos destacados
- Menos de 1 de cada 5 dominios se comparten entre ChatGPT y Google AI Overviews. Las dos plataformas de IA más usadas solo se solapan en el 17.4% de sus fuentes citadas, y están lejos de ser el par menos parecido.
- El 71% de los dominios son exclusivos de un solo modelo de IA. Más de 7 de cada 10 sitios web citados por la IA aparecen en las respuestas de un único modelo. La web que ve cada modelo es, en gran medida, la suya propia.
- El 89% de las URL aparecen en las respuestas de un solo modelo. Los modelos comparten ocasionalmente el mismo sitio web, pero casi nunca citan la misma página. A nivel de página, las fuentes de IA están fragmentadas casi por completo.
- 14.4% de solapamiento promedio de dominios entre dos modelos cualesquiera. Elige dos modelos de IA cualesquiera y, en promedio, comparten menos de 1 de cada 7 de los dominios que citan.
La mayoría de las fuentes son exclusivas de un solo modelo
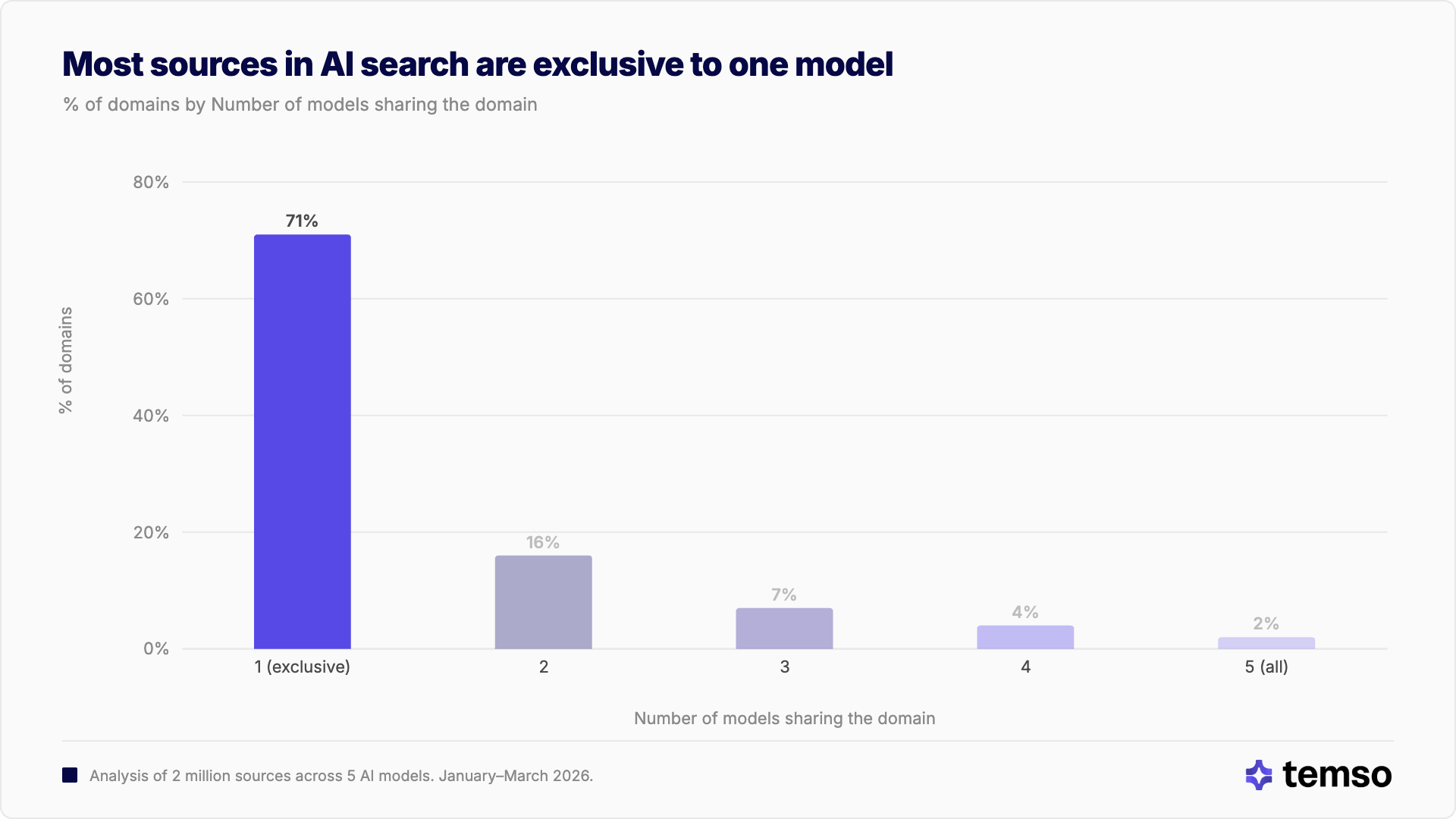
El hallazgo más fundamental: la gran mayoría de las fuentes citadas por los modelos de IA no se comparten. De todos los dominios distintos entre los 5 modelos, el 71.1% aparece en las respuestas de un solo modelo.
La brecha entre la exclusividad de dominios y de URL cuenta su propia historia. Los modelos a veces dan con el mismo sitio web, pero casi nunca citan la misma página. La tasa de solapamiento de dominios es del 28.9%, mientras que la tasa de solapamiento de URL cae hasta solo el 11.2%.
A medida que pasas de "compartido por 1 modelo" a "compartido por los 5", las cifras se desploman:
Solo el 1.6% de los dominios son citados por todos los modelos. Menos de 1 de cada 60 dominios son verdaderamente universales en la IA.
"De los 2 millones de fuentes citadas que analizamos, solo el 1.6% de los dominios son reconocidos por todos los modelos. El resto pertenece al mundo de una u otra plataforma."
Cada modelo tiene su propia huella de fuentes
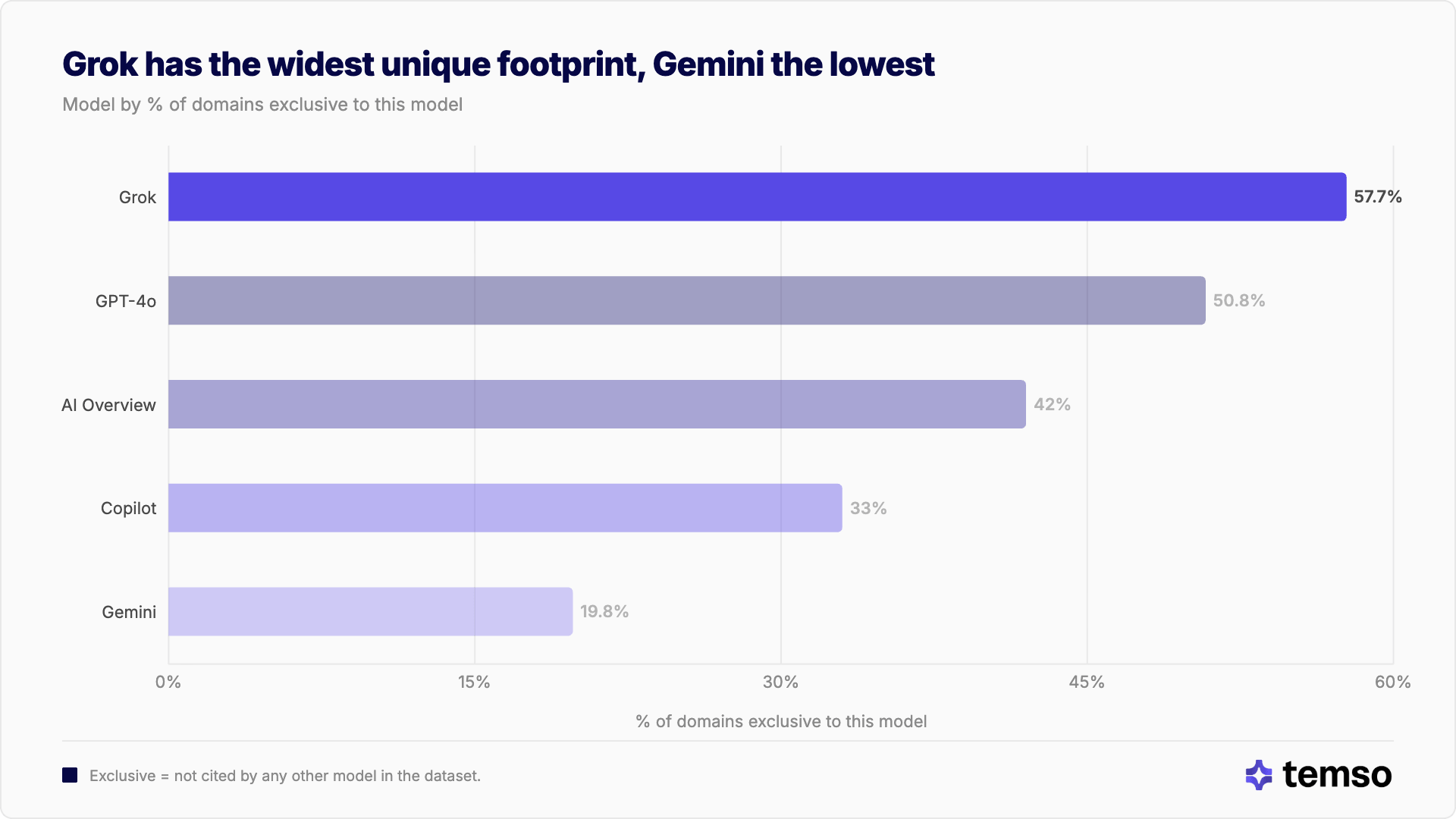
Cada modelo mantiene un conjunto de fuentes claramente distinto. Grok tiene la red más amplia: el 57.7% de sus dominios no son citados por ningún otro modelo. Gemini es lo contrario: solo el 19.8% de sus dominios son exclusivos, lo que significa que más del 80% de lo que cita ya está referenciado por al menos un competidor.
El 85.8% de las páginas específicas que cita Grok no aparece en las respuestas de ningún otro modelo. Cada plataforma está mirando un internet diferente.
"Grok cita más dominios exclusivos de los que la mayoría de los modelos citan en total. Cada plataforma extrae de su propio mapa de la web."
Dos modelos cualesquiera comparten menos de 1 de cada 7 dominios
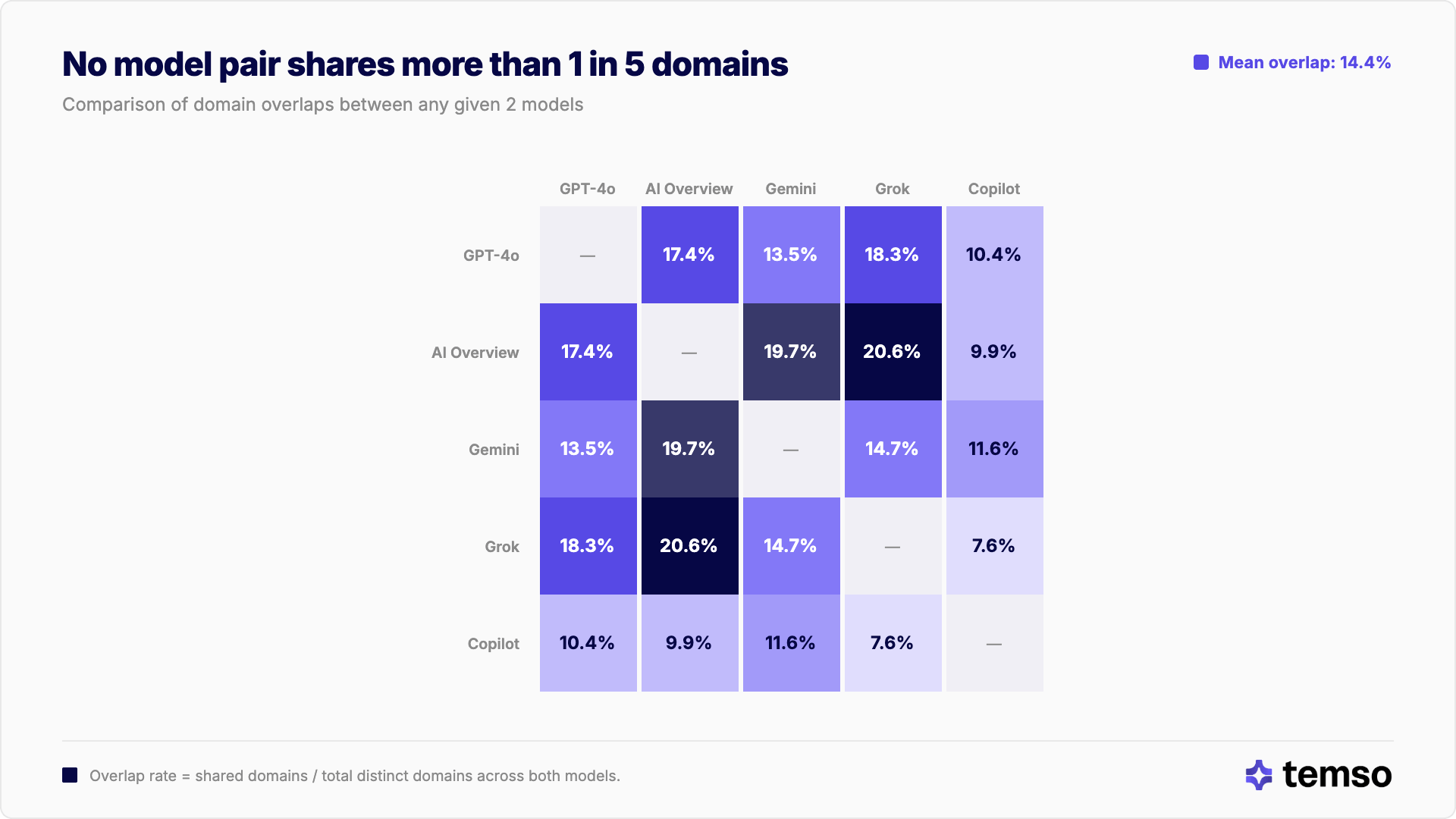
A lo largo de los 10 pares de modelos posibles, la tasa de solapamiento promedio de dominios es del 14.4%. El par más alto (AI Overview y Grok) comparte solo el 20.6%. El más bajo (Grok y Copilot) comparte el 7.6%.
| Modelo A | Modelo B | Tasa de solapamiento |
|---|---|---|
| AI Overview | Grok | 20.6% |
| AI Overview | Gemini | 19.7% |
| ChatGPT | Grok | 18.3% |
| ChatGPT | AI Overview | 17.4% |
| Gemini | Grok | 14.7% |
| ChatGPT | Gemini | 13.5% |
| Gemini | Copilot | 11.6% |
| ChatGPT | Copilot | 10.4% |
| AI Overview | Copilot | 9.9% |
| Grok | Copilot | 7.6% |
Copilot es el modelo más aislado, aparece en los 3 pares inferiores. AI Overview muestra el mayor solapamiento tanto con Grok (20.6%) como con Gemini (19.7%), lo que sugiere un perfil de recuperación más amplio que se cruza parcialmente con varios competidores.
Incluso en el mejor de los casos, 4 de cada 5 dominios no se comparten. Ningún par de modelos se acerca a citar una mayoría de las mismas fuentes.
"Incluso los dos modelos de IA más parecidos discrepan en 4 de cada 5 fuentes que citan. Los menos parecidos casi no comparten nada."
Los modelos más pequeños extraen de fuentes mainstream
Cuando le das la vuelta a la pregunta, de "cuánto solapamiento" a "cuánto de las fuentes de un modelo ya conoce otro", surge una jerarquía. Las citas de los modelos más pequeños son, en gran parte, subconjuntos de las de los más grandes.
| Modelo más pequeño | Contenido en → | % contenido |
|---|---|---|
| Gemini | Grok | 68.3% |
| Gemini | AI Overview | 55.0% |
| Copilot | Grok | 53.6% |
| AI Overview | Grok | 48.7% |
| Copilot | ChatGPT | 46.9% |
| Gemini | ChatGPT | 43.0% |
| Copilot | AI Overview | 41.1% |
| ChatGPT | Grok | 41.0% |
Grok aparece como el destino "contenido en" con mayor frecuencia, ya que se muestra en el lado derecho de esta tabla más que cualquier otro modelo. Más de dos tercios de lo que cita Gemini ya lo conoce Grok. Casi la mitad de los dominios de AI Overview aparecen en el conjunto de Grok. Los modelos más pequeños tienden a citar desde un grupo de fuentes más mainstream y consolidado, mientras que Grok se adentra más en la cola larga de la web.
"Dos tercios de lo que cita Gemini ya lo conoce Grok. Los modelos más pequeños se quedan en el mainstream, mientras que los más grandes exploran los márgenes."
Contexto
Este análisis se basa en datos de citas de fuentes recopilados a través de la plataforma Temso, que monitorea cómo aparecen las marcas en las respuestas generadas por IA. Cada vez que un modelo de IA responde a un prompt y cita una fuente, esa cita se captura y se rastrea.
El conjunto de datos incluye 2,045,102 citas de fuentes provenientes de 134,673 respuestas de IA, abarcando 5 modelos: ChatGPT, Google AI Overview, Gemini, Grok y Copilot. A diferencia de un estudio observacional típico, este análisis es controlado: solo incluye prompts en los que respondieron los 5 modelos, garantizando que cada modelo se compara exactamente sobre el mismo conjunto de preguntas. Estos hallazgos reflejan el comportamiento de citación de los modelos de IA observado a través de prompts comerciales y relacionados con marcas.
Metodología
Cómo lo medimos
Para cada uno de los 5 modelos, recopilamos el conjunto completo de dominios y URL citados en las respuestas a los prompts que cumplían los requisitos. Luego comparamos cada par de modelos posible (10 pares) calculando la tasa de solapamiento: el número de dominios compartidos dividido por el total de dominios distintos entre ambos modelos. Esto ofrece una medida limpia y simétrica de cuán parecidos son los conjuntos de citas de dos modelos.
La decisión de diseño clave en este estudio fue el conjunto controlado de prompts. Al restringirnos a los prompts en los que respondieron los 5 modelos, garantizamos que las diferencias en el comportamiento de citación reflejan verdaderas preferencias a nivel de modelo, y no solo diferencias en lo que se le preguntó a cada uno. Cada modelo en cada comparación respondió las mismas preguntas.
Todas las estimaciones incluyen intervalos de confianza al nivel del 95%. Se sometió a prueba la significancia estadística de la diferencia entre las tasas de solapamiento de dominios y de URL, confirmando que los dos niveles de análisis producen resultados con diferencias significativas.
